GEOとは何を最適化しているのか?AIの仕組みを3層で理解する
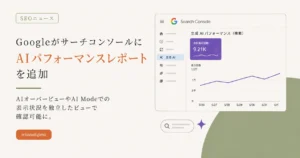
読み終わったあとに持ち帰れること AIがコンテンツを「知る」経路は、トレーニングとリアルタイム検索の2種類ある リアルタイム検索には5つのステージがあり、GEOが効くのはそのうちの後半2つだけ ChatGPT・Gemini・Claude・Perplexityはそれぞれ異なる検索インデックスを参照している 「Googleで上位表示=AIに引用される」は成立しない。インデックスと引用選択は別のシステム 引用されやすいコンテンツの要因は、査読済み学術研究と複数の大規模実測データで確認されている 「GEOをやりましょう」という話が増えてきました。マーケティング担当者だけでなく、ブランドオーナーや経営者からも同じ言葉を聞くようになっています。 ただ、正直に言うと、GEOとは何を最適化しているのか、正確に説明できる人はまだ少ない。「AIに引用されるようにコンテンツを整える」というのは正しい。でもその前に、AIがどういう仕組みでコンテンツを参照しているのかを理解しないと、施策が的外れになります。「Braveに登録しよう」「llms.txtを入れよう」。どちらも間違いではないのですが、なぜそれをするのかが分からないまま動くのはリスクです。 ブランドオーナーの方へ、先にひとつ。GEOは「新しい施策」ではありません。土台はSEOです。これまでコツコツ積み上げてきたSEOの資産が、AI時代の可視性にそのままつながっています。新しいものを追いかける前に、その話を先にしておきたい。 この記事では、AIがコンテンツを参照するプロセスを3つの層に分けて整理します。SEO担当者にとっては施策を評価するための地図として、ブランドオーナーにとっては投資の優先順位を判断するための視点として、使ってください。 AIはどうやってコンテンツを「知っている」のか AIチャットボットがあなたの質問に答えるとき、その知識は2つの経路から来ています。 ひとつは、モデルが公開される前の学習(トレーニング)で焼き付いた知識。もうひとつは、質問が来たときにリアルタイムで検索して取ってくる情報。この2つは、まったく別のシステムです。 「AIに覚えさせる」「AIに学習させる」という言葉が広まったせいで、この2つが混同されています。GEOを正しく考えるには、まずここを切り分けることが先です。 GEOとは何か AIの回答に自分のコンテンツが引用・参照される確率を高めるための最適化。ただしAIがコンテンツを参照するプロセスは一段階ではなく、3つの層に分かれている。どの層に何が起きているかを理解しないまま施策を打っても、空振りになる。 第1層:トレーニングデータ(モデルに焼き付いた知識) AIモデルは公開される前に、膨大なウェブデータを使って学習しています。その中心になるのがCommon Crawl。2008年から運営している非営利団体が提供する公開ウェブアーカイブで、GPT-3ではトレーニングデータ全体のトークンの80%以上がここから取られていました。 Common Crawlはリアルタイムではなく、定期的なスナップショット形式でデータを収集・公開しています。これがカットオフ(知識の締め切り日)が構造的に存在する理由です。カットオフ以降の情報は、この層には存在しません。 自分のサイトがトレーニングデータに含まれているかどうかを確認する方法はありません。GPT-4のトレーニングコストは1億ドルを超えているとSam Altmanが発言しているように、モデルのトレーニングは数ヶ月〜数年単位の大規模プロセスです。個人や企業が後から「学習させる」ことは、仕組み上できません。 この層は、現実的に最適化できる層ではありません。 「AIに学習させる」という表現は正確ではない コンテンツを公開しても、それが現在稼働中のモデルの学習データに追加されるわけではない。トレーニングは大規模なプロセスであり、その対象データを外部からコントロールする手段は現時点で存在しない。 第2層:リアルタイム検索(クエリ時に起きること) リアルタイム検索が発動するとき、AIは単純に「検索して表示する」わけではありません。AI検索システムの研究によれば、すべてのAI検索は共通の5段階パイプラインで動いています。 ステージ 名称…
→ 記事を読む